











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


Python分库分表的几种常见形式
更新时间:2017年12月21日16时08分 来源:传智播客 浏览次数:
“分库分表”是谈论数据库架构和优化时经常听到的关键词。那么对于这些业务量正在高速增长的公司,它有那么容易实践吗?
垂直分表
垂直分表在日常开发和设计中比较常见,通俗的说法叫做“大表拆小表”,拆分是基于关系型数据库中的“列”(字段)进行的。通常情况,某个表中的字段比较多,可以新建立一张“扩展表”,将不经常使用或者长度较大的字段拆分出去放到“扩展表”中,如下图所示:
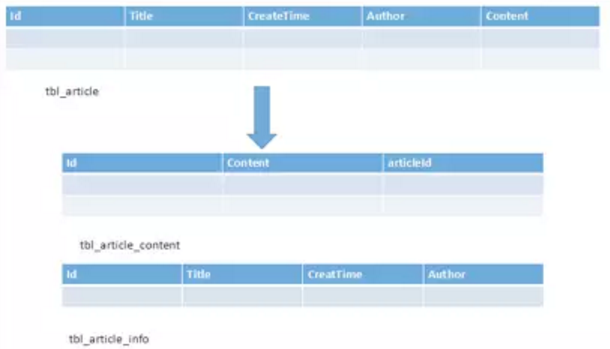
在字段很多的情况下,拆分开确实更便于开发和维护。
拆分字段的操作建议在数据库设计阶段就做好。如果是在发展过程中拆分,则需要改写以前的查询语句,会额外带来一定的成本和风险,建议谨慎。
垂直分库
垂直分库在“微服务”盛行的今天已经非常普及了。基本的思路就是按照业务模块来划分出不同的数据库,而不是像早期一样将所有的数据表都放到同一个数据库中。如下图:
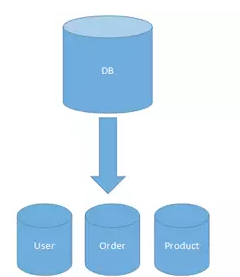
系统层面的“服务化”拆分操作,能够解决业务系统层面的耦合和性能瓶颈,有利于系统的扩展维护。也能对不同业务类型的数据进行“分级”管理、维护、监控、扩展等。
在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈,是大型分布式系统中优化数据库架构的重要手段。
水平分表
水平分表也称为横向分表,比较容易理解,就是将表中不同的数据行按照一定规律分布到不同的数据库表中(这些表保存在同一个数据库中),这样来降低单表数据量,优化查询性能。最常见的方式就是通过主键或者时间等字段进行Hash和取模后拆分。如下图所示:

水平分表,能够降低单表的数据量,一定程度上可以缓解查询性能瓶颈。
水平分库分表
水平分库分表与上面讲到的水平分表的思想相同,唯一不同的就是将这些拆分出来的表保存在不同的数据中。这也是很多大型互联网公司所选择的做法。如下图:
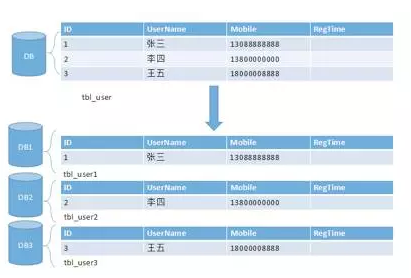
某种意义上来讲,有些系统中使用的“冷热数据分离”(将一些使用较少的历史数据迁移到其他的数据库中。而在业务功能上,通常默认只提供热点数据的查询),也是类似的实践。
在高并发和海量数据的场景下,分库分表能够有效缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源的瓶颈。当然,投入的硬件成本也会更高。同时,这也会带来一些复杂的技术问题和挑战(例如:跨分片的复杂查询,跨分片事务等)
总结和实践建议
1. 我们目前的数据库是否需要进行分库分表?
根据系统架构和公司实际情况来,如果你们的系统还是个简单的单体应用,并且没有什么访问量和数据量,那就别着急折腾“垂直分库”了,否则没有任何收益,也很难有好结果。
切记,“过度设计”和“过早优化”是很多架构师和技术人员常犯的毛病。
2. 有没有原则或者技巧?
没有什么黄金法则和标准答案。一般是参考系统的业务模块拆分来进行数据库的拆分。比如“用户服务”,对应的可能就是“用户数据库”。但是也不一定严格一一对应。
3. 后台系统中join的表都有n个了,其实互联网的业务系统中,本来就应该尽量避免join的,如果有多个join的,要么是设计不合理,要么是技术选型有误。
本文版权归传智播客人工智能+Python学院所有,欢迎转载,转载请注明作者出处。谢谢!
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
